

1. Robots.txt blocking layered navigation parameters
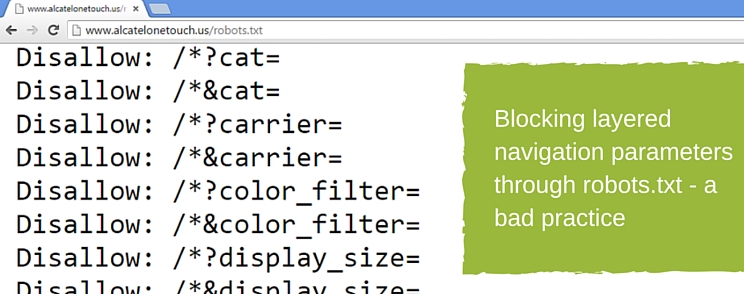
While in most cases you really don’t want to get your layered navigation or other filtering and sorting parameters on your category pages indexed by Google, blocking them with a robots.txt disallow is not an optimal way of handling this thin content issue.
The reason is, they can still be indexed, they just can’t be crawled. To understand the difference between robots.txt disallow and meta noindex read this.
The robots.txt disallow approach throws a lot of good link juice from internal navigation away. Instead of disallowing those parameters through robots.txt file, you really want to use meta noindex, follow on URLs with those parameters instead.
Once again, don’t do both robots.txt disallow and meta noindex, follow as Google will not be able to see the meta noindex, follow on your URL as they wouldn’t be able to crawl it due to your robots.txt disallow.
2. Robots.txt NOT blocking the site search results

While disallowing layered parameters through robots.txt file is a bad practice, what you really want to disallow are your site search results, or in most implementations, specifically the /catalogsearch/ URL path.
Google’s Panda algorithm is known to penalize websites that – among other things – allow indexation of large amounts of their site search data. Why? Because Google doesn’t like displaying search results within search results meaning they don’t want to index your site search and they want you to stop them.
Some Magento 2 websites not only forgot to disallow the site search results through their robots.txt file, they actually actively link to their site search results from homepage. They linked the homepage logos of different brands to site search with that brand name as a query parameter.
This is probably done due to lack of some sort of “shop by brand” extension for Magento 2 at the time of development of the website in question. Although I wouldn’t go this way and in most cases I’d choose brand to actually be a category. With visual merchandiser you can fill the brand category automatically with products that match a certain value of your manufacturer or brand product attribute. You can read more about planning your navigation as well as what to do with brand pages in terms of SEO here.
3. Missing availability in schema.org microdata markup for product offer
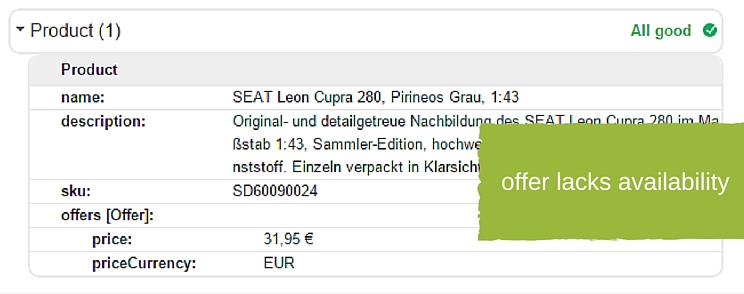
Microdata markup helps Google and other major search engines understand the content of your pages. It helps them figure out what’s your price, what’s your special price, your reviews and so on.
It is not just a feature that helps you get a better CTR as you can read in our case study.
It’s also a feature necessary for automatic product updates for Google Merchant Center. Since we’re missing the availability markup, neither SERP results will be featuring our product as “In stock” nor will automatic availability product updates within the Google Merchant Center work.
Since this is important aspect for both SEO and PPC as explained above, this is something worth looking into and fixing.
4. Pointing layered URLs back to category with rel canonical
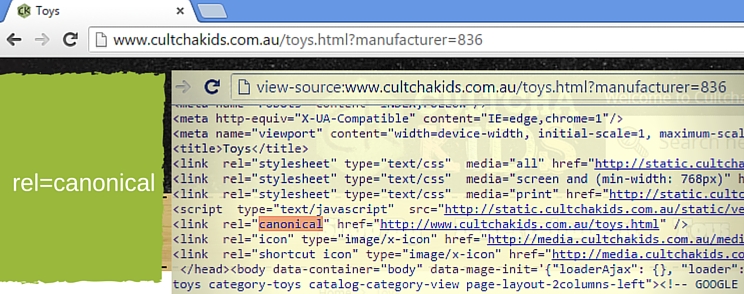
Rel canonical is not intended to be used in this way. When Google introduced rel canonical, it was supposed to solve the issue of duplicate and near duplicate content. Since layered filters actually change the content of the URL (show a different product collection – a narrowed one – and in some cases even an extended one with multi select attributes that expand the product collection) they are not duplicates.
While you usually don’t want to have all those layered URLs in index as they create thin content issues (notice, there’s a difference between thin and duplicate content in SEO terminology and they are solved in different ways), you shouldn’t look towards rel canonical to solve this issue (much like the case with robots.txt disallow from the first example in this article).
What you really want is to place meta noindex, follow on those layered URLs and thus get them out of index while allowing the link juice to flow through them through your navigation and product listings to other pages that you need to rank.
5. Indexing both http and https versions of the website
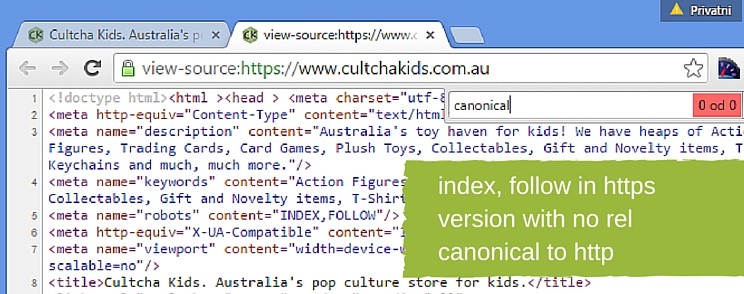
Having http and https versions of the same URL indexed is a great example of duplicate content and a great example of where rel canonical should be used to consolidate the duplicates into a prefered version. If the https version is the prefered one (and it should be since Google considers https to be a ranking factor), the http version of the same URl should have a rel canonical pointing it to https version, or if http is the prefered version the https version should point its canonical towards it.
6. Homepage title "Home page"

Homepage is usually your strongest page in terms of link equity and the page that can rank for your most important keywords. For this reason, it’s not a good idea to have its title say "Home page" as that doesn’t describe what your website is all about.
Original source: http://inchoo.net/online-marketing/common-magento-2-seo-mistakes/
Thanks for reading!


